RAG
1. 引言
随着自然语言处理(NLP)技术的迅猛发展,生成式语言模型(如GPT、BART等)在多种文本生成任务中表现卓越,尤其在语言生成和上下文理解方面。然而,纯生成模型在处理事实类任务时存在一些固有的局限性。例如,由于这些模型依赖于固定的预训练数据,它们在回答需要最新或实时信息的问题时,可能会出现“编造”信息的现象,导致生成结果不准确或缺乏事实依据。此外,生成模型在面对长尾问题和复杂推理任务时,常因缺乏特定领域的外部知识支持而表现不佳,难以提供足够的深度和准确性。
与此同时,检索模型(Retriever)能够通过在海量文档中快速找到相关信息,解决事实查询的问题。然而,传统检索模型(如BM25)在面对模糊查询或跨域问题时,往往只能返回孤立的结果,无法生成连贯的自然语言回答。由于缺乏上下文推理能力,检索模型生成的答案通常不够连贯和完整。
为了解决这两类模型的不足,检索增强生成模型(Retrieval-Augmented Generation,RAG)应运而生。RAG通过结合生成模型和检索模型的优势,实时从外部知识库中获取相关信息,并将其融入生成任务中,确保生成的文本既具备上下文连贯性,又包含准确的知识。这种混合架构在智能问答、信息检索与推理、以及领域特定的内容生成等场景中表现尤为出色。
2. RAG 的基本原理
RAG 的基本原理是,通过检索模型从外部知识库中获取相关信息,并将其融入生成模型中,生成更连贯和准确的文本。具体步骤如下:
- 检索器:通过检索模型从外部知识库中检索相关的信息。
- 生成器:负责生成最终的自然语言输出。
2.1 检索器
- 向量检索:将外部知识库中的文本转化为向量,并与用户输入的文本进行相似度计算。向量检索的优点在于能够更好的捕捉语义相似性,而不仅仅是依赖于词汇匹配。
- 关键词检索:主要基于词频和逆文档频率(TF-IDF)的加权搜索模型来对文档进行排序和检索。BM25适用于处理较为简单的匹配任务,尤其是当查询和文档中的关键词有直接匹配时。
2.2 生成器
- 文本生成:通过生成模型生成自然语言文本。
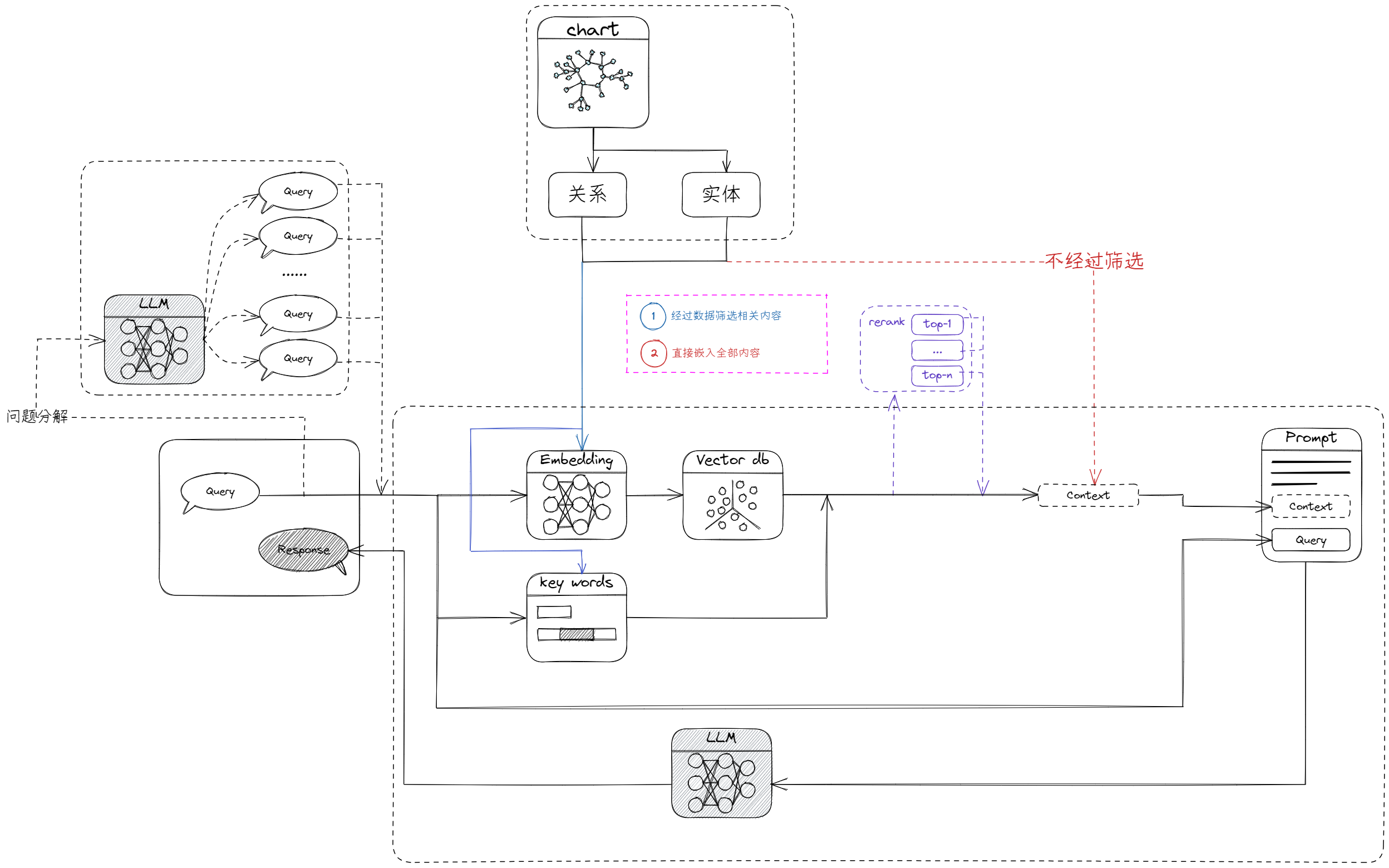
2.3 项目的RAG工作流程
输入:通过用户输入的问题,分解出多个关键词。
检索:根据关键词,在知识库中进行检索,获取相关的文本。
生成:将检索到的文本与用户输入的问题一起,作为输入,让生成模型生成自然语言文本。
输出:将生成的答案反馈给用户。
3. RAG 的优势与不足
3.1 优势
- 信息完整性:RAG 模型结合了检索与生成技术,使得生成的文本不仅语言自然流畅,还能够准确利用外部知识库提供的实时信息。这种方法能够显著提升生成任务的准确性,特别是在知识密集型场景下,如医疗问答或法律意见生成。通过从知识库中检索相关文档,RAG 模型避免了生成模型“编造”信息的风险,确保输出更具真实性 。
- 知识推理能力:RAG 能够利用大规模的外部知识库进行高效检索,并结合这些真实数据进行推理,生成基于事实的答案。相比传统生成模型,RAG 能处理更为复杂的任务,特别是涉及跨领域或跨文档的推理任务。例如,法律领域的复杂判例推理或金融领域的分析报告生成都可以通过RAG的推理能力得到优化 。
- 领域适应性强:RAG 具有良好的跨领域适应性,能够根据不同领域的知识库进行特定领域内的高效检索和生成。例如,在医疗、法律、金融等需要实时更新和高度准确性的领域,RAG 模型的表现优于仅依赖预训练的生成模型 。
3.2 不足
RAG(检索增强生成)模型通过结合检索器和生成器,实现了在多种任务中知识密集型内容生成的突破性进展。然而,尽管其具有较强的应用潜力和跨领域适应能力,但在实际应用中仍然面临着一些关键局限,限制了其在大规模系统中的部署和优化。
RAG模型的性能很大程度上取决于检索器返回的文档质量。由于生成器主要依赖检索器提供的上下文信息,如果检索到的文档片段不相关、不准确,生成的文本可能出现偏差,甚至产生误导性的结果。尤其在多模糊查询或跨领域检索的情况下,检索器可能无法找到合适的片段,这将直接影响生成内容的连贯性和准确性。
- 挑战:当知识库庞大且内容多样时,如何提高检索器在复杂问题下的精确度是一大挑战。当前的方法如BM25等在特定任务上有局限,尤其是在面对语义模糊的查询时,传统的关键词匹配方式可能无法提供语义上相关的内容。
- 解决途径:引入混合检索技术,如结合稀疏检索(BM25)与密集检索(如向量检索)。例如,Faiss的底层实现允许通过BERT等模型生成密集向量表示,显著提升语义级别的匹配效果。通过这种方式,检索器可以捕捉深层次的语义相似性,减少无关文档对生成器的负面影响。